ブログページからのブログ関連情報取得
これは元々2009/11/09にAmebloに投稿した記事です。
RFC2616: Hypertext Transfer Protocol -- HTTP/1.1
PHP DOM XML extension encoding processing []
入力補助機能
今回は名前のフリガナのカナからローマ字への変換に引き続き、登録/入力作業の補助機能を実装します。
WebAPIの利用やカナのローマ字変換により、個人データの登録はかなり楽になったものの、
テーマ:AKB48やテーマ:東京ガールズコレクション09AWのような、大量のブログがあるテーマの登録作業では、
余にもブログ情報の登録が単純作業過ぎる為にうんざりしましたので、それを改善すべく機能を追加します。
# Blogara的には、映画やTVドラマのように数件しかブログが無いテーマに比べると非常に有り難い存在ですが。
ここではブログのURLをフォームに入力し、
URLで指定されたHTMLからタイトルとFeedURLを取得するという単純な機能の実装を行います。
フォームの入力とAjaxリクエスト
登録作業と処理の流れとしては、
ブログURL入力フォームに追加したブログ情報を取得ボタンのクリックにより
フォームに入力されたブログURLをサーバーにAjaxで送信。
サーバー側スクリプトではその指定URLをリクエストしHTMLを取得、
そのHTMLからタイトルとFeedURLを抽出し、Ajaxリクエストのレスポンスとしてクライアントに返す。
クライアントでは、レスポンスからタイトル/FeedURLを取得し該当フォームに値を設定。
タイトルが長すぎる場合にはpowered by なんちゃらなどの部分を適宜(手動で)削除し登録。
と、なります。
Ajaxは、Blogaraの管理フォームで使われるFormCtrlに搭載される機能を使い、
ボタンクリックによる反応や、レスポンスを受け取った後の処理もJavaScriptで行いますが、
今回の記事では、PHPによるサーバー側の処理をメインに記述します。
PHPでの実装
HTTPとHTML
PHPでのHTTPリクエストとHTMLデータの解析という事で、
基本的には共有Feedの管理の回と同様のものとなり、かなりの部分を流用出来ますので、
既にBlogaraに実装されている各種クラスを利用します。
今回はXMLでは無くHTMLデータですが、このようなケースを想定?して、
XMLとHTMLを同様に扱えるDOMDocumentの利用を選択した事は、どうやら正解だった模様です。
DOMDocumentのencoding
DOMDocument(PHP 5.2.10)では、各種メソッドを使ったノード値や属性値の取得を行った場合には、
自動的に文字エンコードがUTF-8に変換された文字列となります。
ただしそれが保証されるのは、文字エンコードが明示的に指定されている場合だけになります。
XMLでは、先頭のXML宣言(<?xml version...)でencoding属性を使い指定されている文章が殆どですが、
HTMLでは、相変わらずmetaタグのhttp-equiv="Content-Type"のcontentで、
charsetが指定されていない残念なページが多数存在し、また現在も生産され続けています。
文字エンコードが指定されていない文章をloadXMLやloadHTMLで読み込んだ場合には、
DOMDocumentのencodingデータメンバにはNULLが設定され、エンコード不明扱いとなります。
XMLの場合には、元がUTF-8以外の文字コードのデータでは非ascii文字?が出現した時点で
UTF-8では無い文字が含まれているというWarningを吐きloadXMLも失敗しますが、
元の文字コードがUTF-8ならそのまま通常通りUTF-8でのデータの取得が出来ます。
一方HTMLの場合には、元が非UTF-8かつ非asciiな文字コードでは勿論、
元がUTF-8のデータであっても、変換後はUTF-8でも無い文字化けした文字列となります。
さらにHTMLのヘッダでcharsetが指定されている場合でも、
そのmetaの前にtitleなどで日本語などが使われている場合には、
encoding不明と同様に文字化けが発生しますので、loadHTMLを使う時には注意が必要です。
またXHTMLの場合には、metaでのcharset指定では無く、xml宣言でencoding指定が行われていればokのようです。
Blogaraではencodingが不明なHTMLデータに対しては、
HTTPヘッダのContent-Typeでcharsetが指定されている場合にはその設定を使い、
それも指定されていない場合には、mb_detect_encodingで文字コードを検出し、
元のデータの<head>を
<head><meta http-equiv="Content-Type" content="text/html; charset='.$encode.'" />
で置き換えるという($encodeには文字エンコード文字列が指定)、
あまり深く考え無い強引な手法で変換し、もう一度loadHTMLでデータを読み込ませるようにしています。
追記: (2009/11/10)
その後DOMDocumentとencodingについて、
PHP DOMDocument encoding loadHTMLあたりでググってみますと、
ZendFrameworkのチームメンバーの方が書かれたDOMDocumentと文字コードの関係についての記事が見付かり、
要するに文字エンコードが未指定のHTMLの場合には、元の文字コードをISO-8859-1だと判断して、
それをUTF-8に変換している為奇妙な事になっていた模様です。
一方loadXMLの場合にはdefaultでUTF-8として扱っていたために、UTF-8のデータならokという事です。
ブログタイトル
ブログURLで指定されたHTMLをDOMDocumentに読み込んだ後は、そこから目的のデータを取り出します。
ブログのタイトルは、Feedのtitleでは無くこのHTMLのtitleから取得します。
$blogInfo = array(); $title = $this->doc->getElementsByTagName( 'title' ); if ( $title && $title->length ) $blogInfo['title'] = $title->item(0)->nodeValue;
FeedURL
FeedのURLは、linkタグのtype属性を見て判断し、そこのhref属性で指定されたURIをFeedURLとして取得します。
またRSSのバージョンなどはtitle属性で指定されているケースが多いですので、title属性も利用します。
ブログサイトによってはFeedが複数タイプ(RSS1.0/2.0 Atom0.3/1.0など)配信されている場合がありますので、
HTMLのヘッダに記述されている全ての候補をXPathで取得した後、
BlogaraでのFeedの優先順位(RSS2.0 > RSS1.0 > Atom1.0)に従いFeedURLを1つ決定します。
$nodeList = $this->xpath->query( "//link[@type='application/rss+xml'] | //link[@type='application/atom+xml']" );
if ( $nodeList && $nodeList->length )
{
$feed = array();
foreach ( $nodeList as $item )
{
$cur = array();
$node = $item->attributes->getNamedItem('href');
if ( $node )
$cur['feed'] = $node->nodeValue;
if ( !$cur['feed'] ) continue;
$node = $item->attributes->getNamedItem('title');
if ( $node )
{
if ( preg_match( '/((?:RSS(?:\s*\d\.\d)?)|(?:Atom))/iu', $node->nodeValue, $ma ) )
$cur['type'] = strtolower( preg_replace('/\s/u','',$ma[1]) );
}
if ( !$cur['type'] ) $cur['type'] = 'unknown';
$feed[$cur['type']] = $cur['feed'];
}
}Feedの存在確認
FeedURLが決定した後はそのFeedが実際に存在しているかの確認を行います。
ブログサイトでは一般的にブログHTMLとFeedXMLを同じシステム上で生成していますので、
ブログHTMLに記述されているFeedが存在しないという事はあまり考えられませんが、
リダイレクトで飛ばす"一部の"ブログサイトも存在しますので、
存在確認と共に無駄なトラフィックを減らす為にリダイレクト先の現在有効なFeedURLを取得します。
for ( $n = 0; $n < 3; $n++ )
{
// redirectに従うのは2回まで。
$ret = $this->checkURL( $blogInfo['feed'], $head );
$resHead = &$ret['head'];
if ( $resHead['_stat']['status'] == '200' ) break;
else if ( strncmp($resHead['_stat']['status'],'3',1) !== 0 || !$resHead['Location'] ) {
$blogInfo['feed'] = '';
break;
}
$blogInfo['feed'] = $resHead['Location'];
}
HTTP HEAD/GET
上記のFeedのチェックでは、HTTP GETでリクエストを送っています。
存在確認だけならHTTP HEADを使えば良さそうなものですが、
"一部の"Webサーバーでは、GETのリクエストでは302 Foundを返すにも拘わらず、
同一URIのリクエストに対し、何故かHEADでは302 Foundを返さずに200 OKを返す面倒なサーバーがあるので、
GETで行う事になりましたというオチです。
RFC2616: Hypertext Transfer Protocol -- HTTP/1.1には、
The metainformation contained in the HTTP headers in response to a HEAD request SHOULD be identical to the information sent in response to a GET request.
とあるので、GETと同じヘッダを返すべきだけであって、そうしなければならないという訳でも無いので、
そのサーバーがそのようなアレな仕様だと納得するしかありませんが。
操作
ブログURL欄にURLを入力し、ブログ情報を取得をクリックすると、
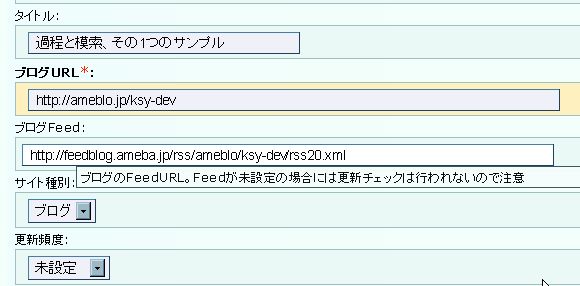
大抵は1秒も掛からずに、タイトルとFeedURL欄には実際のHTMLから取得した値が設定されます。
入力補助機能
今回は大した事は行っておらず実装も簡単ですが、
何十件何百件も入力を行う際には地味ながらにもかなり役に立つ機能となります。
入力作業のようなUIのユーザービリティというものは、初期の設計段階で全てを想定するのは難しく、
このように実際に利用してみたユーザーからのフィードバックでさらに機能性が向上する典型的な要素ですので、
UI周りは柔軟性/拡張性を持った設計/実装にすべきだと思われます。
# 一人開発/運営体制のBlogaraのように開発者=ユーザーとなるケースは少ないでしょうが、
# 実際に開発側の人間がそれなりに使い込んでみるのが一番判りやすいのかもしれません。:)
参考資料
PHPマニュアル: DOMDocument::loadHTML - DOMDocumentのHTMLデータでの文字エンコードの扱いについてRFC2616: Hypertext Transfer Protocol -- HTTP/1.1
PHP DOM XML extension encoding processing []